








Proficiently manipulate the UniProt database
 source:Technical division
source:Technical division date:2022-06-09
date:2022-06-09 views:815
views:815
1,Introduction and use details of Uniprot protein database
Uniprot database is the most widely resourced and most informative protein database, and the first choice for querying protein functions. The Uniprot database consists of three sub-databases, Swiss-Prot, TrEMBL and PIR-PSD. The data mainly comes from the whole-gene protein sequences obtained after the genomes of each species are sequenced, and contains many proteins and their functional information from the literature. Especially in the swiss-prot sub-database, the protein information in the library is manually checked, non-redundant, and protein data with detailed annotation information. As a scientific researcher, the use of Uniprot database skills should be one of the necessary skills.
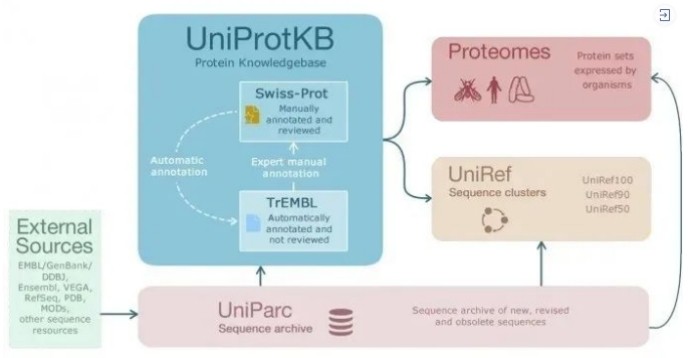
- UniProtKB (UniProt Knowledgebase) is the access center for protein sequence, function, classification, cross-reference and other information; UniProtKB is mainly composed of two parts: UniProtKB/Swiss-Prot: High-quality, hand-annotated, non-redundant datasets; mainly from research results in the literature and E-value verification results from computational analysis. Only data with quality assurance is added to the database; UniProtKB/TrEMBL: This dataset contains high-quality computational analysis results, generally enriched in automatic annotation, mainly to cope with the large data flow obtained by the genome project and the shortage of time and labor in manual verification. Annotate all available protein sequences. Coding sequences annotated in the three major nucleic acid databases (EMBL-Bank/GenBank/DDBJ) were automatically translated and added to this database. It also has sequences from the PDB database, as well as sequences predicted by Ensembl, Refeq and CCDS genes;
(2) UniRef (UniProt Non-redundant Reference) combines closely related protein sequences into one record in order to improve search speed. At present, three sub-libraries are formed according to the degree of sequence similarity, namely UniRef100, UniRef90 and UniRef50;
(3) UniParc (UniProt Archive) is a comprehensive non-redundant database containing protein sequences from all major, public databases. Since proteins may exist in different databases, and there may be multiple versions in the same database, in order to eliminate redundancy, UniaraParc only saves each unique sequence once, regardless of whether it is a sequence of the same species, as long as the sequence is the same are merged into one, and each sequence provides a stable and unique number UPI. This database contains sequence information for proteins without annotation data. In the UniProt database, UniProtKB/Swiss-Prot is the most commonly used. Today we mainly introduce the use of this database. We enter CCL4L2 in the input field, click search, and the detailed information of the protein in different species will appear. Find the species entry we want and click to enter.
The main sub-databases of the Uniprot database are composed of:
|
Database name |
Full name |
Database characteristic |
|
UniprotKB/Swiss-Prot |
Protein knowledgebase(review) |
High-quality, hand-annotated, non-redundant database |
|
UniprotKB/TrEMBL |
Protein knowledgebase(unreview) |
Automatic translation of protein sequences, predicted sequences, unvalidated databases |
|
UniParc |
Sequence |
Non-redundant protein sequence database |
|
UniRef |
Sequence clusters |
Clustering sequences reduce the database and speed up searches |
|
Proteomes |
Protein sets from fully sequenced genomes |
Proteomic information for species with fully sequenced genomes |
The relationship between the above sub-databases is as follows: uniprot will collect raw data such as protein sequences and functional information in public databases such as EMBL, GenBank, DDBJ, etc., and store them in the non-redundant protein sequence database of UniParc after processing; UniPrc is used as a data warehouse, and then separately Provide reliable datasets for UniProtKB, Proteomes, UNIRef, among which Swiss-Prot in UniProtKB database is a high-quality non-redundant database obtained by manual annotation by TrEMBL, and it is also one of our most commonly used protein databases.
Uniprot database official link: https://www.uniprot.org/
- Single protein information query The following figure is the homepage of the official website of Uniprot. Enter the protein ID or Accession number in the UniprotKB column, and then click search to query the protein function.
We take HUMAN CCL4L2 as an example to search for its information in the Uniprot database, as shown in the figure below, the page displays the Entry mode by default, and the page displays include: protein name, species origin, GO functional annotation, subcellular localization, tissue-specific expression, Information on interacting proteins, Domains, sequence information, homologous proteins, and other data links.


Click the Publications button under Display, and the database will display the published articles for this protein.
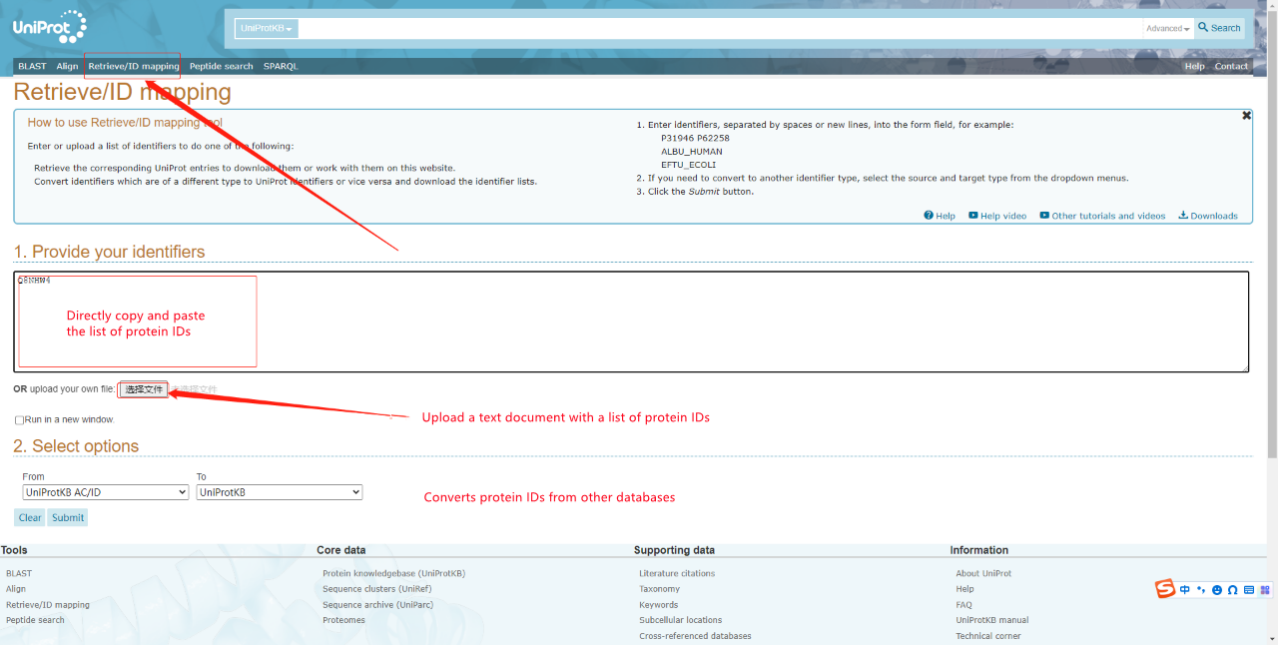
- Batch protein information query If there are many proteins to be queried, you can click Retrieve/ID mapping on the task bar in the first row, as shown in the figure below, the query protein list can be directly pasted in the text box of Figure 1. Provide your identifiers, or you can paste the protein ID column in TXT Text submitted to the website. In addition, the page 2. Select options can also provide ID conversion function to support ID conversion between multiple databases.
After submitting the protein list, click Submit, and the website will automatically analyze the results. The results are displayed as follows: The displayed information includes: protein corresponding gene name, protein description, sequence length and other information.
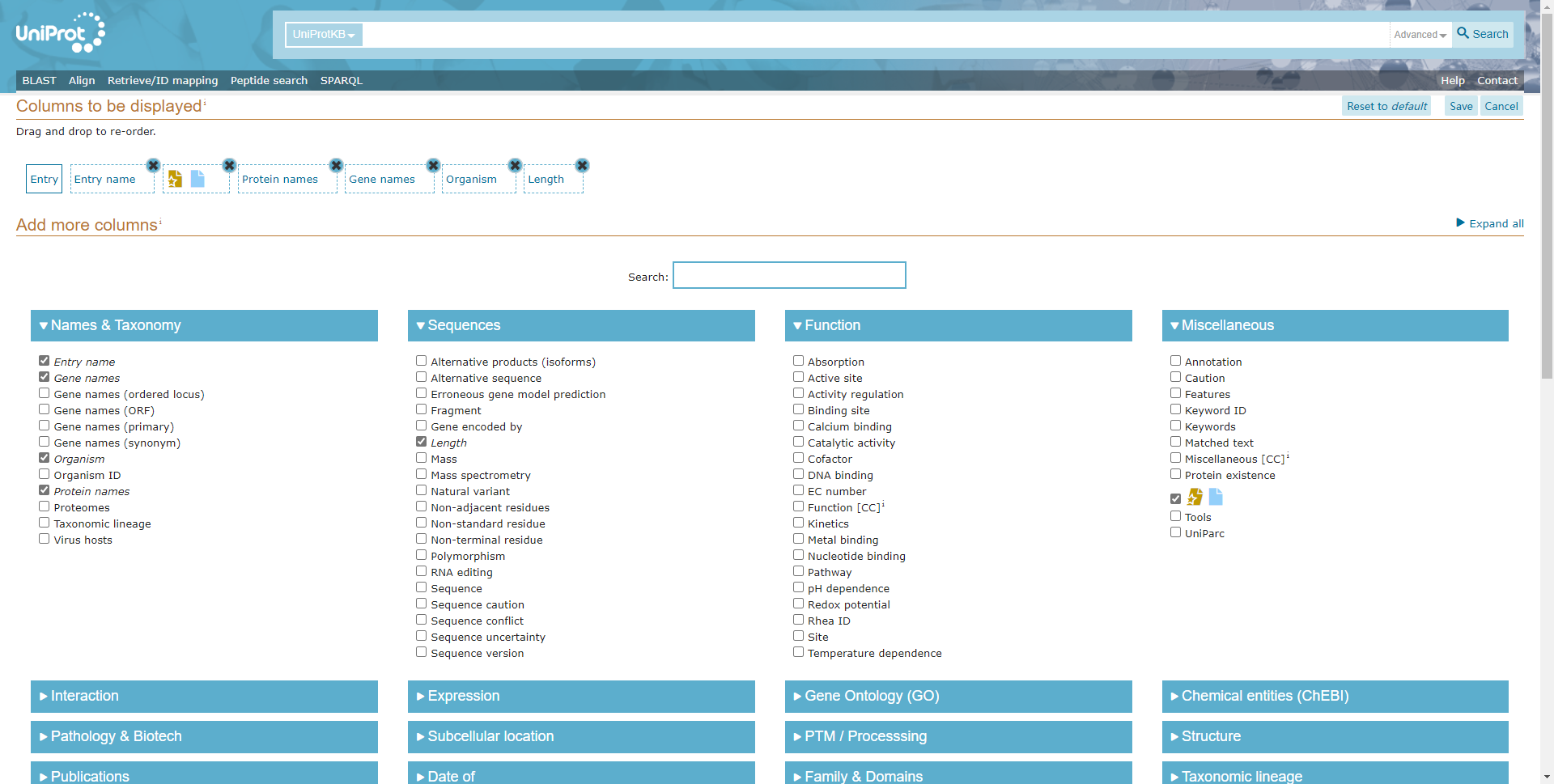
Click the Column button to select the database information to be displayed, such as annotation information such as GO, pathway, and subcellular positioning, as shown in the figure below. After selecting, click save to save the settings, and the system will automatically jump to the information display page.
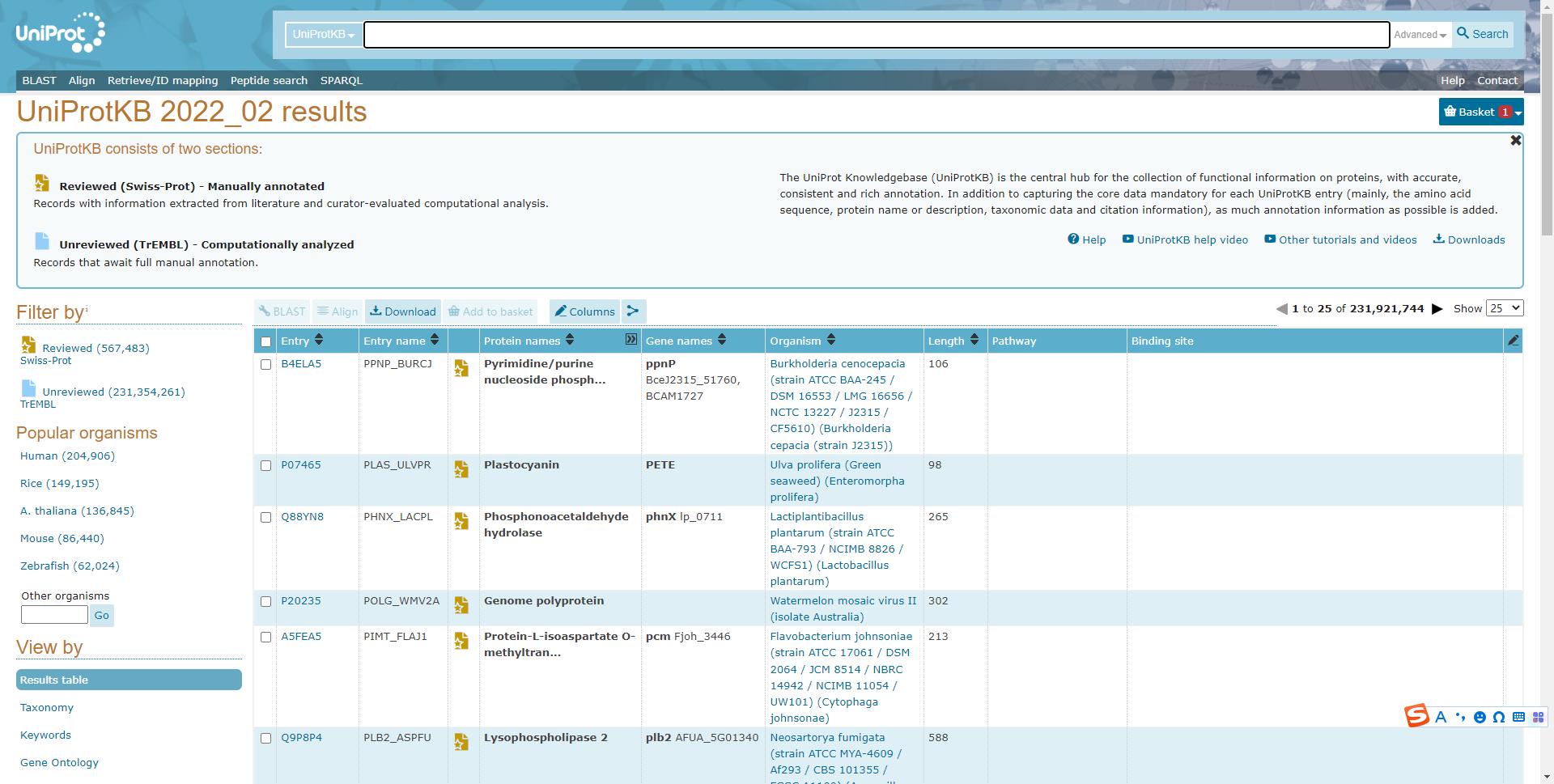
The final result is shown in the figure below, check the protein of interest, you can download the annotation results to the local view, and support a variety of text formats including Excel format.
Names & Taxonomyi
For scientific research reagent sales workers, this section is used more often. This section displays the naming (including protein name, gene name) and source species information. If necessary, you can directly jump to the NCBI and Enzem databases. make an inquiry.
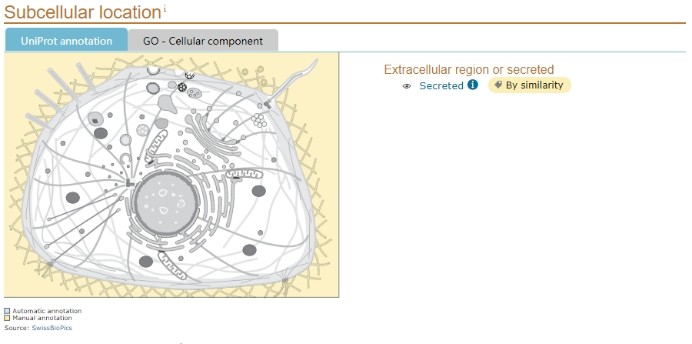
Subcellular location
This is followed by the subcellular localization and topology of the protein. It can be seen that CCL4L2 is a secreted protein located outside the cell membrane
PTM / Processingi
In the PTM section, the information on protein synthesis, molecular processing, amino acid modification and post-translational modification, such as cleavage, glycosylation, fatty acylation, and disulfide bond positions, is listed, and the signal peptide sequence of this protein can be known. and precursor proteins are listed together.
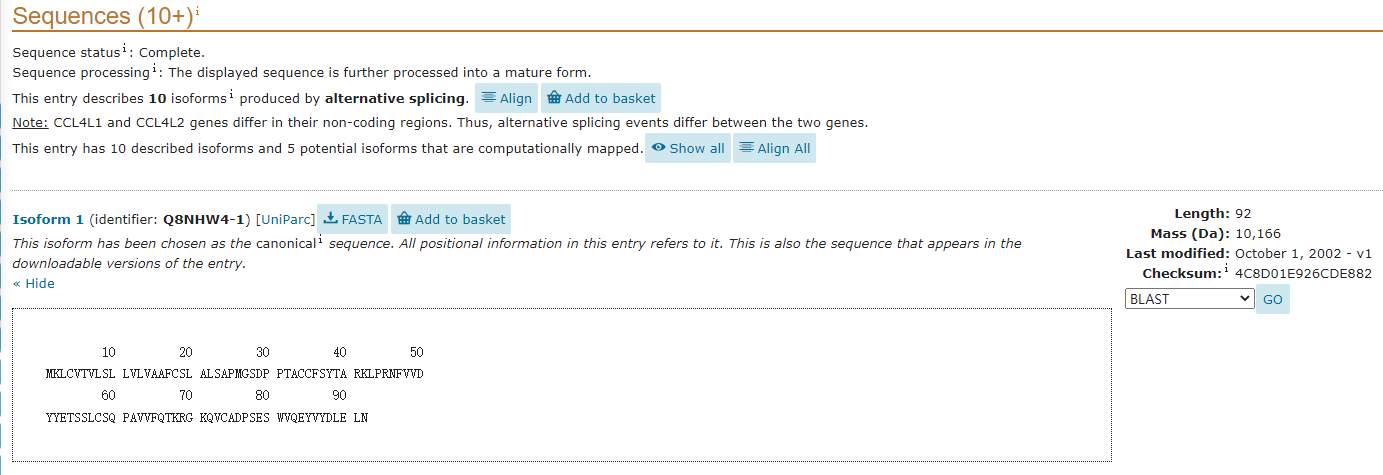
Sequences (10+)i
The sequence part is the important information that scientific researchers need. This part lists the complete sequence of the protein starting from the signal peptide. If the protein has different splicing bodies, the sequence of each splicing body will also be listed one by one. It is convenient for researchers to use.
The introduction of Uniprot database is finished, I hope it will be helpful to your scientific research!

 RETURN
RETURN